Where does Latency come from in Enterprise-Storage-Systems and what can Enterprises do to minimise it
We dive into the Storage-Stack, ride on Storage-Protocols and give hints, why Dell, VMware, Intel and NVIDIA is a good combo in the fight for better Workload Performance
Latency is delay. Everyone knows the waiting time when calling up a web page until all content is displayed and loaded. The faster something loads, the better the user experience. This is also true in the enterprise. There, it’s primarily database entries or documents that need to be accessed as quickly as possible. If it takes too long, employee satisfaction drops and, at some point, so does productivity. Latency can also be business-critical. Search engines often display the results with the fastest load times first. If you’re not in the top two, the conversion happens elsewhere; valuable sales opportunities are lost. Dell Technologies and its partners have declared war on latency. But first, a few basics.
Note for IT managers or budget owners: You really do not know exactly what’s under the hood when buying hardware or designing an architecture. But you should understand your technicians and know how to separate the wheat from the chaff and what questions you should ask the manufacturers to avoid getting marketing crap.
Where does latency come from?
Every application — as different as it may be — has one thing in common: The more data has to be moved, the slower it gets. It is irrelevant whether it is read or write access.
The distance that the data has to travel plays a major role. The combination of hardware and software used is also not unimportant. The network protocols used and the choice of storage media are also relevant. Serialisation plays its part, too. This involves converting objects into byte sequences in order to transfer them over a network or store them in files.

Classic, proprietary scale-out architectures are just as helpless in the face of all this as more modern cloud technology like Ceph.

Each wait increases latency by an average of 5 milliseconds.
Oversize me
First of all, poor latency can be excellently masked with a focus on IOPS and throughput. Both cloud service providers (CSPs) and vendors like to resort to this. The trick is called overprovisioning: beat physics with metal.
With overprovisioning, there are more resources deployed than an application needs. The utilisation point is higher than the actual workload. This waste has several disadvantages at once:
- It’s expensive.
- It scales only to a point.
- It takes up more space.
- It consumes more power.
- It requires more infrastructure, including cooling.
The whole thing is like a bottomless pit. In addition to higher initial costs, the operating costs also increase. And don’t even get me started on the environmental impact.
It is therefore worthwhile to start with the transmission path. Bypasses and specialised protocols have a direct impact on speed.
I know a shortcut
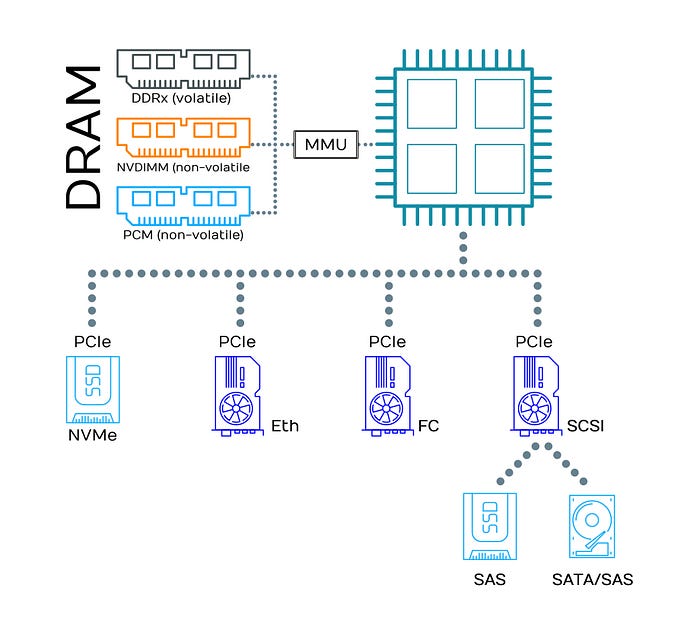
Every operating system has several storage layers (the storage stack). There are already some good approaches at the block level. However, most applications use file or record access and cannot directly access the block interface (block API).
Remote Direct Memory Access (RDMA) dumps data directly into the network. They simply bypass things like the processor (CPU), cache, and operating system kernel. In the case of CEPH, depending on the type of access, the detour via service gateways, kernel modules, libraries and metadata servers is omitted. Application and storage communicate directly with each other. This avoids bothersome context switches and the intermediate storage of data. And workloads can also be parallelised.

RDMA is implemented in Virtual Interface Architecture, RDMA over Converged Ethernet (RoCE), InfiniBand, iSER (an iSCSI extension), Omni-Path and iWARP. RDMA can also be used by virtual machines (VM). In addition to DirectPath I/O (also called passthrough or passthru) to the Host Channel Adapter (HCA) or RDMA-enabled network interface cards (NIC) are an option. To support vSphere features like vMotion with DirectPath I/O, Paravirtual RDMA (PVRDMA, vRDMA) is required.
There is also some movement in the market here right now. Challenger Vcinity wants to turn the WAN into a global LAN and promises lossless transmission rates at distances of more than 250,000 km for 10G or up to 25,000 km even for 100G systems — independent of data and applications, without compression, deduplication or other data manipulation. The startup relies on open standard protocols for client and WAN interfaces and wants to integrate transparently into existing hybrid and multi-cloud infrastructures.
Flash without Gordon
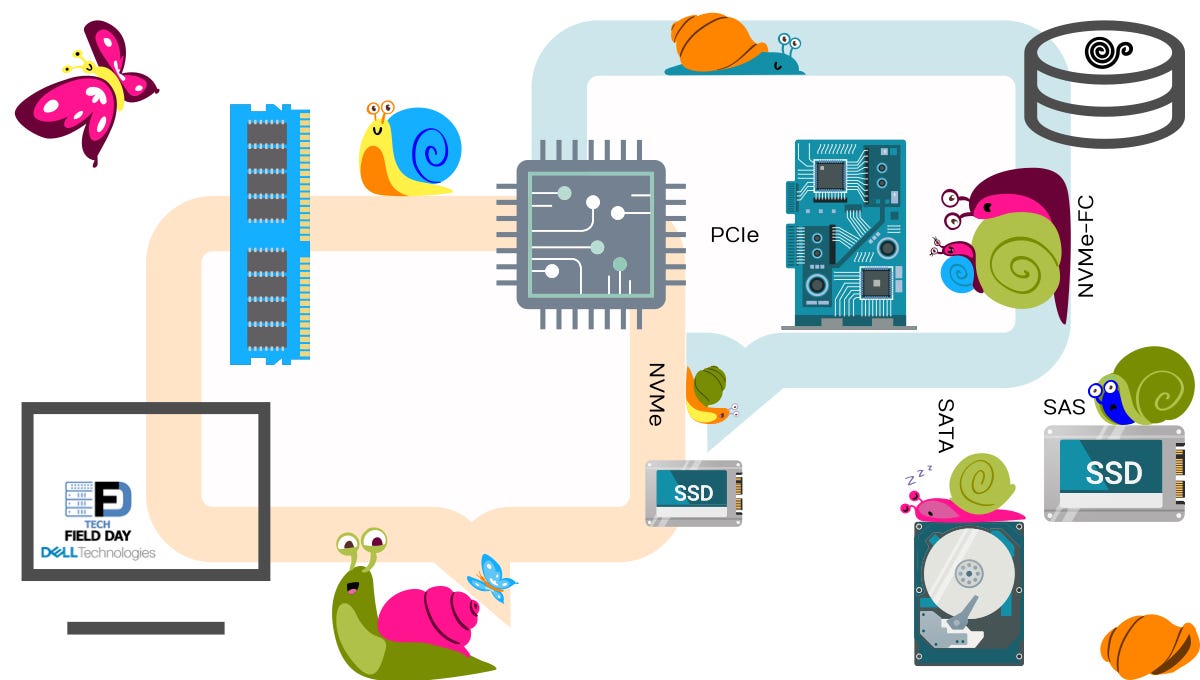
SSDs are actually to blame for all this. Whereas the hard disk used to determine speed, the network is now the limiting factor. In fact, traditional storage protocols are lagging behind. One answer is NVMe or NVMe-oF (Non-Volatile Memory Express, as SAN over Fabric). NVMe uses PCI Express (PCIe).
Enterprise-grade flash memory comes in the form of solid state disks (SSDs) in classic hard drive form or as memory bars for DIMM slots. SSDs are usually NAND memory. DIMM modules are available with NAND or 3D NAND technology (NVDIMM) or as phase change memory (PCM). EDSFF-based Intel® Data Center SSDs (formerly known as Ruler SSD) are a special form of common SSD. EDSFF stands for Enterprise & Data Center SSD Form Factor. And although the EDSFF modules from Intel® are called Optane, they are still just NAND storage.
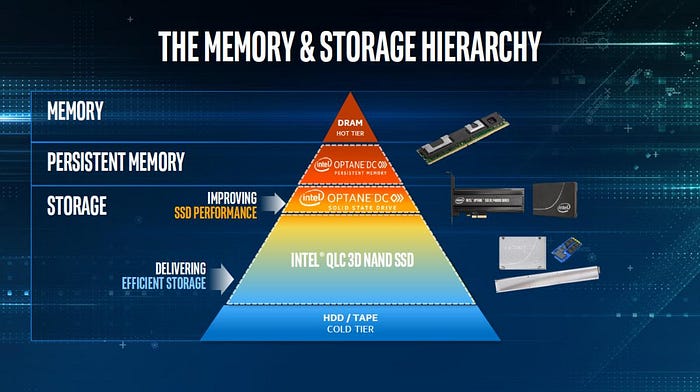
Flash storage media can be addressed more or less directly by the processor. Actually each core can communicate independently with the storage. Another option is to bring the data closer to the CPU. Storage Class Memory is fast non-volatile memory in DRAM. This type of memory is commonly known as persistent memory (PMEM, PRAM) or non-volatile RAM (NVRAM). We will use the term NVRAM hereafter.
NVRAM is accessed via the CPU’s memory management unit (MMU). The latency is in the lower two-digit nanosecond range. PCM is still somewhat faster than NVDIMM-F (Dual In-line Memory Module with Flash Memory). This is due to how the information is stored: NVDIMM is based on NAND flash technology. To store information, electrons are bound in floating gates or, in the case of 3D NAND, charge traps. Without drifting too deeply into quantum mechanics: a change of state is possible either through the so-called tunnel effect (complicated!) or the injection of hot charge carriers (hot-carrier injection). Both demand time and stress the memory physically. The latter also explains the comparatively short lifetime of a NAND-flash memory the more often it is written to or overwritten. With phase change memory, the electrons simply change direction. This is drastically faster than binding it and is also much more gentle on the material. PCM therefore has a longer lifetime than NAND flash — measured in write operations, not in absolute time. The higher endurance should be factored in at the time of procurement.
ESG has validated the performance differences between NAND SSDs and PCM with Intel® Optane™ technology for Dell and summarised it in a paper.
SSDs are addressed with NVMe either directly via PCIe or in the SAN via RDMA in the form of NVMe over Fabric (NVMe-oF). In terms of latency, we are now in the range of ±100 microseconds.
Of course, SSDs can also be addressed with SAS. We do not recommend this. Please also read our article about NVMe and SSDs. Note: the article is in German. Meanwhile, NVMe is also available via Fibre Channel (FC). We do not recommend this in the long run either. Ethernet switches are simply so much cheaper and more flexible. Besides, there are now many more Ethernet admins than FC admins. In general, only interfaces and protocols that have been developed for specific purposes should be used. Flash memory, for example, should always be addressed directly with NVMe. Anything bent for something (SAS-SSD) or wrapped in something else (NVMe over FC) means performance and time loss.
SAS has another disadvantage. Like SATA, the number of commands in the command queue is limited. In contrast to SATA (32 commands), SAS already supports 256 commands. But: NVMe supports up to 64k queues with 64k commands each. If you want to know exactly, you can find more information in the blog at Simms.
By the way, with SCSI drives we have arrived at latencies of about 15 milliseconds.
And with that we close the circle. Now the networkers have to come up with something and, above all, leave their silos. Storage and networking can no longer be separated.
Tiers without fears
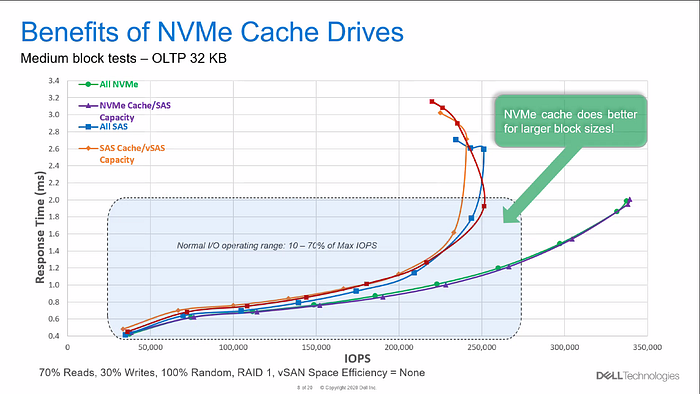
In order to process ever-increasing amounts of data (and files) and meet the demands of modern workloads such as machine learning (ML) or artificial intelligence (AI), new approaches are needed. SSD caching is one of them. In this process, frequently required data is temporarily stored in NVRAM modules. This reminds us a bit of tiering in classic storage architectures — there, too, frequently used (hot) data is stored in flash memory media directly on the storage node.
Dell uses SSD caching in its next-generation VxRail nodes and relies on Intel® Optane™️ technology:
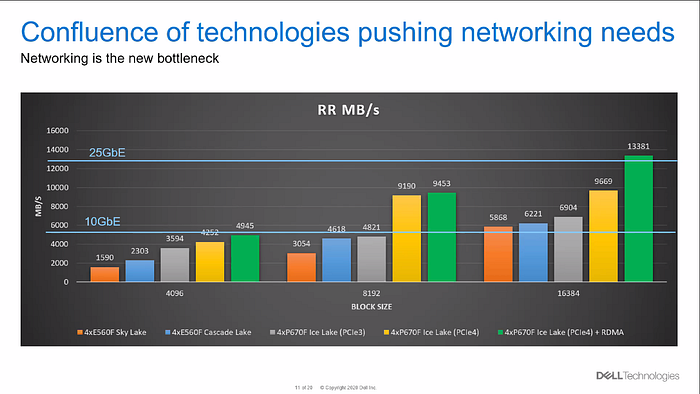
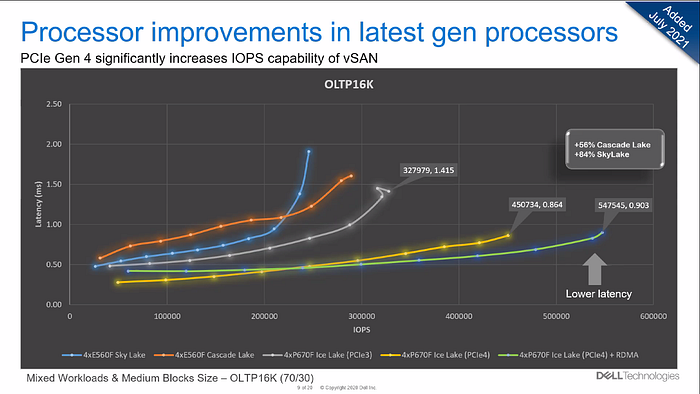
Processors also play a role in the battle for faster runtimes. Moreover, choosing the right processor is not only crucial for latency. The number of computing operations also increases significantly. Dell has taken a look at this in a second benchmark.
For even better values, we remove the separation between compute node and storage. We converge hyper. Let’s take a closer look at Dell’s VxRail. For better understanding, we’ll answer a question first: what is hyperconvergency?
Hyper! Hyper! Hype?
The idea behind hyperconverged systems is simplification. Instead of designated network, storage or compute nodes, a little bit of everything is packed into one or more height units.
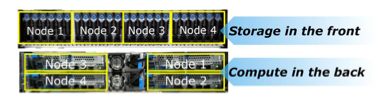
Software decides what of it should be used and how. The biggest advantage of these standardised blocks (building blocks) is the ability to expand or shrink capacity as easily as possible. This applies to both the procurement side and the technical execution.
But as always every coin has two sides: Depending on what the node is used for, the rest is left unused and takes up space. You also have to pay for it — both at the time of purchase and during operation. This could not be concealed for long. That’s why we now have Composable Disaggregated Infrastructure. Here you also have building blocks, but again separated into storage, network and compute. Cloud technology (again software) sticks everything together and knows what is needed when and in what size. By the way, we know this principle from mainframe architecture.
If more capacity was needed, a few modules were (not quite so) simply added or more cards were plugged in. In modern data centres, of course, this is much more agile and convenient. Virtualization makes it possible.
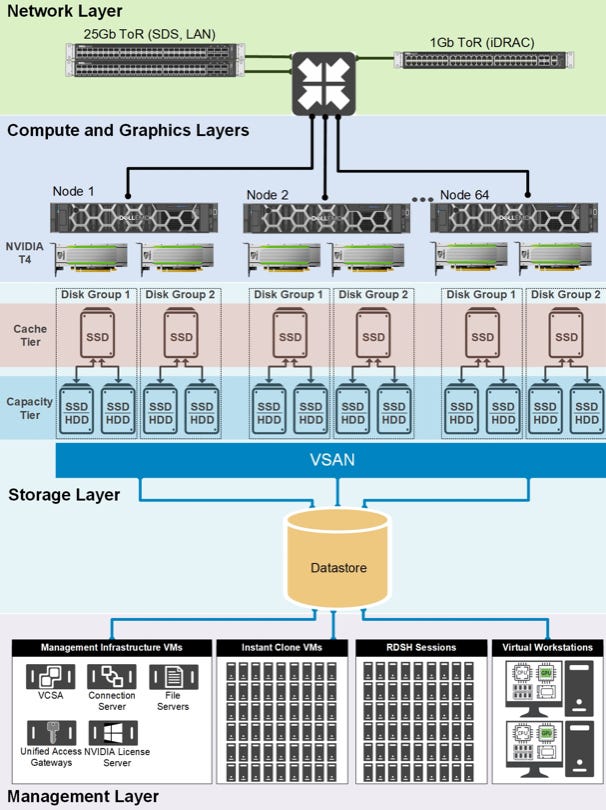
Everything that the data center has to offer is virtualised: Networks, servers and storage. Even processors!
I want more … uh … less … more …
For certain applications, even the best processors quickly reach their performance limits. Especially when HPC applications such as machine learning, fluid dynamics or 3D modelling enter the normal corporate routine. Desktop virtualisation (VDI) is also becoming increasingly demanding. It is not only since Corona that users expect the same service levels at the remote workplace as in the office. Virtual desktops have therefore been relying on the superpower of graphics processors (GPU) for a long time.
Dell knows this too and has equipped its VxRail appliances with powerful NVIDIA GPUs. NVIDIA vGPU software allows physical GPUs to be split into multiple virtual units. This allows containers or virtual machines (VMs) to allocate their own resources.
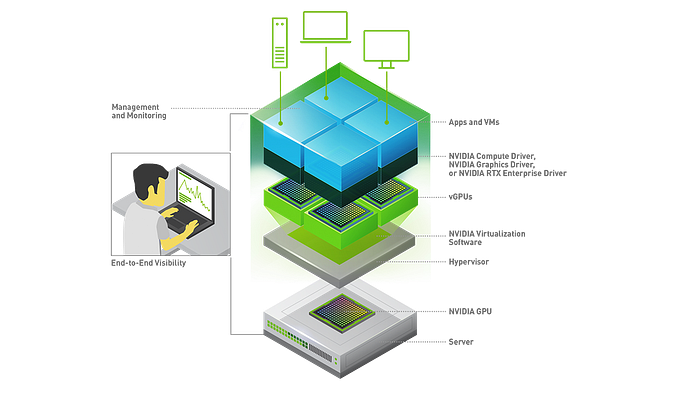
SmartNICs and dedicated data processors (DPU) from NVIDIA are other building blocks for which VxRail appliances are certified — along with the available software zoo.
Back to protocols: VxRail supports GPUDirect RDMA, but unfortunately not NVLINK yet. NVLINK is a multilane high-speed GPU connection developed by NVIDIA for multi-GPU systems. The communication is extremely much faster than PCIe connections, partly because it uses a mesh instead of a hub topology. If you want that, you have to switch to Dell’s Isilon solution or ask Supermicro and Boston. There, NVLINK is already available in relatively ordinary servers (the ANNA series).
Let’s look at the big picture now. Everything up to here has been quite a bit of theory. What does it look like in the wild at Dell?
Fully meshed
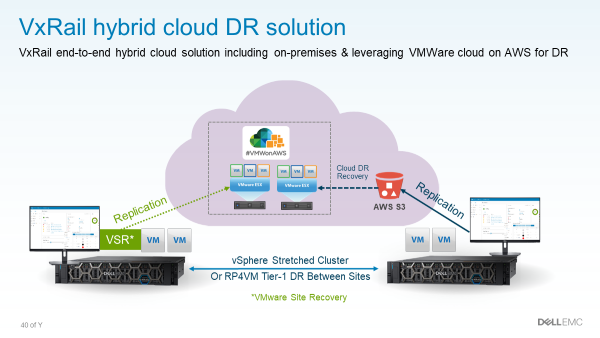
Dell EMC’s VxRail has been developed for and with VMware. Therefore it is optimised for exactly one purpose: To support VMware in the best possible way. VxRail seamlessly integrates with VMware Cloud Foundation and of course has everything on board that the VMware universe has to offer. And because it is an end-to-end cloud solution, in addition to vSAN, VxRail also supports vSAN HCI Mesh. In this way, metro clusters can be built, among other things. As use cases, Dell now mentions Instand Recovery in addition to classic failover scenarios. We’ll have more to say about that in a moment.
The smaller boxes are also suitable for operation at remote or branch offices (ROBO).
AppsOn!
While VxRail still supports HDD and SSD equally, with PowerStore Dell EMC has developed a powerful all-flash storage appliance. And although it’s labeled with Store(age) on it, Dell itself sees it as an infrastructure platform.
Notable in PowerStore is the AppsOn feature — what brings us back to eliminating latency. With AppsOn PowerStore allows virtualised VMware workloads to run directly on the array. This is made possible by an integrated VMware vSphere. AppsOn is great for data-heavy applications but also for anything that requires low latency. Dell cites edge or analytics applications as examples, but also monitoring software and security programs such as antivirus scanners. In the cluster, applications can be seamlessly pushed from one node to another.
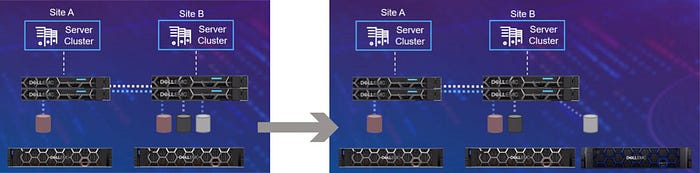
PowerStore is also available as a metro node. The clusters are active-active. Dell EMC lists three modes for its clusters: asynchronous, synchronous and metro-synchronous. For the latter, the vendor promises both zero RPO and RTO.
RTO: How long does it take to restore normal operations after a disaster?
RPO: How much data can a company lose during a disaster?

Since in this mode both cluster sides appear as a unit to the outside world and both are probably mirrored in real time, we believe that to be the case for now. But! This is especially handy in the event of a ransomware attack, as both instances can be encrypted simultaneously. In any case, we still recommend a serious disaster recovery strategy. And proper backups. Seriously!
According to the manufacturer’s website, the cluster communicates with NVMe FC. *le sigh* Our favourite problem child, Fibre Channel: NVMe does not make it more sympathetic. NVMe over Fibre Channel is made up of NVMe over Fabric (NVMe-oF) and FC-NVMe. For transport, NVMe is pressed into Fibre Channel frames by a Host Bus Adapter (HBA). On the other side, it has to be unpacked again accordingly. This literally screams for overhead and higher latency.
Small comfort: iSCSI is also supported. That makes sense because of investment protection. However, if Dell really wants to position itself as a partner of the Next Generation, the manufacturer should urgently focus on the more efficient NVMe-oF (without FC!) now and at least offer it in parallel. The PowerStore technical data sheet can be found on the manufacturer’s website.
Though we want to finish with something positive and quickly take a look at the management GUI. We discovered something really nice: the physical view.
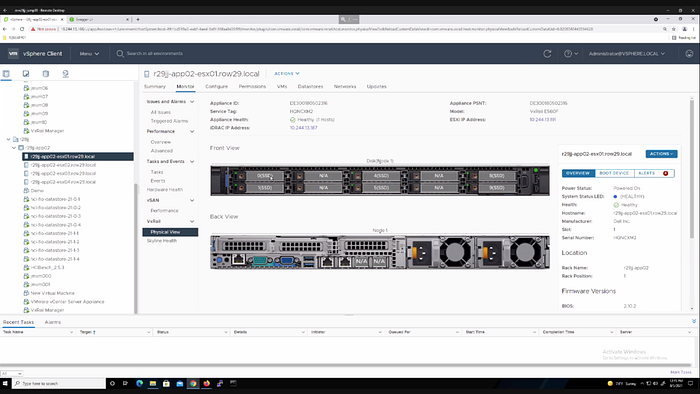
This is of course also available in VxRail:
Conclusion
Dell EMC’s PowerStore and VxRail are both powerful, modern solutions with a few really innovative extras. If you already have Dell in the house, you can stay with it (for now) with a clear conscience.
If all this is not enough, you should also look into computational storage. Or invest in a supercomputer.
All presentations from the Tech Field Day Presents Dell Technologies HCI & Storage (TFDxDell21) were recorded and can be found on the Tech Field Day pages.
Dell has linked to a detailed description of Storage Class Memory on the Training Center home page.
For the sake of completeness, here are Dell’s collected works in an overview. Why PowerEdge is declared as coming soon here is beyond our knowledge.
This article has been published originally in German on data-disrupted.de.
